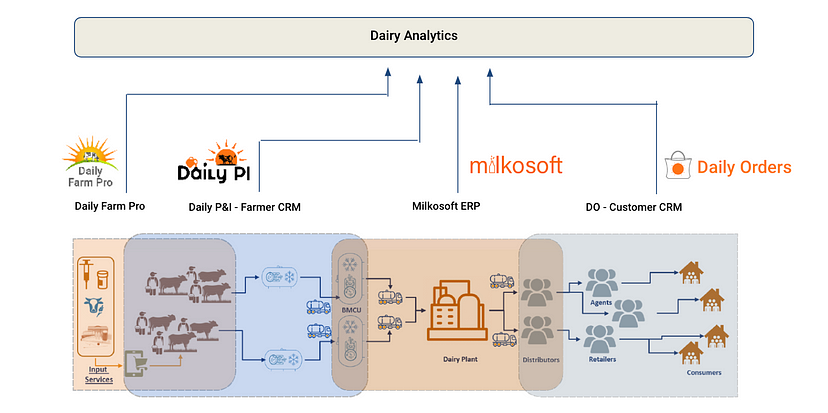
Usage across our core products (Milkosoft and Daily Orders) has exploded during the past few years with daily traffic volume doubling every year. While all our products are SaaS offerings, we support various multi-tenant deployment models including separate application deployment for large Milkosoft clients (complete isolation), single application but separate database for smaller Milkosoft clients and single application, single database for Daily Orders. Milkosoft application usage usually peaks out once it gets fully deployed across all departments within the dairy.
Since Daily Orders is a single application, single database multi-tenant deployment, it needs to scale massively to handle the ever-growing new clients that are being on-boarded and as existing clients add more workloads to track their secondary sales. Most clients give the mobile app to their customers and all sales orders are booked via the mobile app either directly by their customers or by their sales teams. Apart from order booking, the app is used by clients to manage their entire sales operations which includes sales logistics and delivery tracking (including reverse logistics), field-force management, asset tracking and digital payments. Since dairy operations are 24×7 with some of the most critical operations happening in the night and early hours, the application is expected to have 100% uptime and 24x7x365 availability. There’s literally no downtime maintenance window available which can be challenging during major architecture-related upgrades!
Daily Orders started off as a traditional monolith application but as usage grew we had to rework the architecture to enable it to scale infinitely in a cost-effective way. We re-worked the data tier as well as the application tier to ensure that these can be scaled independently. Since our application footprint is large we needed to ensure that these changes had minimal impact on the application code in order to minimize the risk of any regressions.
Given that Daily Orders is a highly database intensive application, it was very critical for us to ensure that the data layer was not only highly tuned but also set up for scaling horizontally. At the data tier we partitioned the schema by grouping together entities logically. We also did some denormalization within schema partitions so that these schemas could be run on separate database instances which can then further be replicated to scale horizontally. Our ORM layer had support for logically grouping entities and each grouping can be mapped to a database instance. Without any code changes and tweaking configurations we were able to achieve this.
We created an extra indirection within our ORM layer which encapsulated the load-balancing logic to fetch the appropriate database instance based on the configured database instances. After all, as the maxim goes “All problems in computer science can be solved by another level of indirection”! The nice thing about these changes is that application code modifications were minimal and we could also easily switch between monolith and partitioned databases deployments based on a few configuration settings. This allowed dev and test instances of Daily Orders to be easily deployed on a single database instance and for production we could scale up the database instances as needed.
At the application layer we were adding more nodes as traffic continued to grow. As we added more location based services in the app (to track field movements, capture field images/notes, etc) for both field-staff and vehicles monitoring, we saw a huge spike in highly-parallel bursty workloads of short jobs. Adding additional nodes was always an option but we wanted to explore other ways to scale which would be more cost-effective for us.
We experimented with AWS Lambda and we found that it was a great fit for these types of workloads. So we moved a lot of these newer services to AWS Lambda and front-ended these with our Apache web server (and AWS API Gateway). It turned out to be very cost-effective as well for us since for a few dollars a month we were able to serve up these huge volumes of requests! Routing all requests through our Apache frontend prevents vendor lockdown which is important for us since it gives us the option to seamlessly switch to other serverless backends whenever needed. The corresponding partitioned schemas to support these serverless services were deployed in the same datacenter to take advantage of the gigabit bandwidth connectivity and also eliminate any data transfer costs.
We also adopted AWS S3 extensively across the application to manage all digital assets (including user generated content) that were getting generated either within the application (images, documents, invoice pdfs, etc) or were getting synced from third party systems (such as external invoices, customer account statements, etc). This allowed us to scale to handle tens of millions of assets that are accessed by users through our mobile and web interfaces.